Sự cố API Anthropic đột ngột ngừng hoạt động do lệnh cấm hành chính khẩn cấp từ Chính phủ Mỹ vừa qua đã đẩy hàng loạt hệ thống Agentic AI của các doanh nghiệp vào kịch bản tồi tệ nhất: sập nguồn hoàn toàn trên Production. Đối với các Tech Lead và Solution Architect, thảm họa diện rộng này không chỉ là một bài toán vận hành thông thường, mà là một minh chứng đắt giá cho khái niệm SPOF (Single Point of Failure - Điểm nghẽn chí mạng duy nhất) khi hệ thống phụ thuộc hoàn toàn vào một nhà cung cấp API duy nhất.
Khi dòng mô hình thế hệ mới Claude Fable 5 và Mythos-class biến mất khỏi môi trường đám mây, các ứng dụng Agentic AI và hệ thống xử lý dữ liệu lớn (Big Data pipelines) sử dụng context window khổng lồ lập tức bị gãy đổ dây chuyền. Bài viết này sẽ hướng dẫn bạn thiết kế lại kiến trúc hệ thống theo mô hình Multi-LLM và thiết lập các chiến lược Failover (tự động chuyển mạch) bền vững nhất để bảo vệ ứng dụng của bạn.
1. Giải mã hậu quả từ sự cố API Anthropic trên Production
Rất nhiều kỹ sư cho rằng việc chuyển đổi LLM chỉ đơn giản là đổi một dòng mã cấu hình api_key hoặc đổi tên mô hình từ claude-fable-5 sang gpt-4o. Trên thực tế, khi sự cố API Anthropic xảy ra đột ngột, các hệ thống Production đã gặp phải ba thảm họa kỹ thuật dây chuyền:
- Sự lệch pha cấu trúc đầu ra (JSON Schema Drift): Các mô hình Agentic AI cao cấp hoạt động dựa trên kỹ thuật Structured Outputs (Trả về dữ liệu có cấu trúc định sẵn). Khi hạ cấp đột ngột từ Fable 5 xuống các mô hình đời cũ như Claude 4.8 Opus hay các mô hình của đối thủ, cấu trúc định dạng JSON đầu ra thường bị lệch (drift). Điều này khiến tầng Parser (phân tách dữ liệu) của hệ thống phía sau bị crash, dẫn đến lỗi hệ thống hàng loạt.
- Mất mát ngữ cảnh lớn (Context Window Truncation): Dòng Mythos-class hỗ trợ cửa sổ ngữ cảnh lên tới 1 triệu Tokens. Nhiều kỹ sư đã lạm dụng điều này để nhồi toàn bộ cơ sở dữ liệu vào Prompt (In-context Learning) thay vì xây dựng hệ thống RAG (Retrieval-Augmented Generation) chuẩn chỉ. Khi buộc phải chuyển đổi sang các mô hình có Context Window nhỏ hơn, dữ liệu lập tức bị cắt xén (truncate), khiến AI mất khả năng suy luận chính xác và đưa ra các kết quả sai lệch hoàn toàn.
- Xác suất lỗi hệ thống tăng vọt: Trong một hệ thống đơn lẻ (Single-provider), độ khả dụng của ứng dụng bị phụ thuộc hoàn toàn vào uptime của nhà cung cấp đó. Giả sử độ khả dụng của API Anthropic là 99,5% (tương đương với khoảng 43 giờ downtime mỗi năm). Khi xảy ra sự cố địa chính trị hoặc nghẽn mạng cục bộ, toàn bộ ứng dụng của bạn sẽ lập tức ngừng hoạt động.

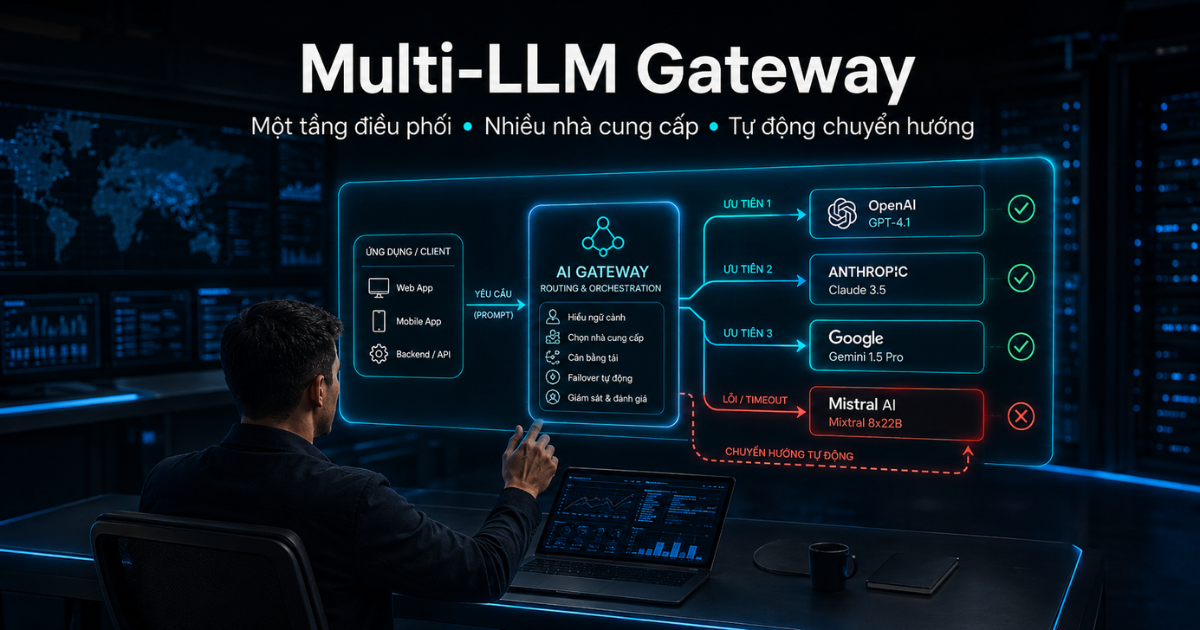
2. Kiến trúc Multi-LLM: Giải pháp sống sót tối thượng cho ứng dụng AI
Để giải quyết triệt để bài toán này, các hệ thống AI hiện đại bắt buộc phải chuyển dịch sang Kiến trúc Multi-LLM. Thay vì kết nối trực tiếp đến API của một nhà cung cấp, chúng ta đặt một tầng AI Gateway (Tầng trừu tượng hóa API) ở giữa ứng dụng và các dịch vụ LLM.
┌──────────────────────┐
│ Client Application │
└──────────┬───────────┘
│ (OpenAI-compatible Request)
▼
┌──────────────────────┐
│ AI Gateway │
│ (LiteLLM / Portkey) │
└────┬────────────┬────┘
│ │
(Primary) │ │ (Fallback)
┌────────────────▼┐ ┌▼────────────────┐
│ Anthropic API │ │ OpenAI API │
│ (Claude Opus) │ │ (GPT-4o) │
└─────────────────┘ └─────────────────┘
Mô hình này mang lại khả năng phục hồi đáng kinh ngạc nhờ vào toán học xác suất. Nếu chúng ta tích hợp song song hai nhà cung cấp độc lập (ví dụ: Anthropic và OpenAI) với cùng độ tin cậy , xác suất để cả hai nhà cung cấp cùng sập đồng thời (khiến hệ thống của chúng ta ngừng hoạt động) được tính bằng công thức nhân xác suất.
Nhờ kiến trúc dự phòng này, độ khả dụng lý thuyết của hệ thống được nâng lên mức 99.9975%, giảm thiểu thời gian sập nguồn từ vài chục giờ xuống chỉ còn dưới 13 phút mỗi năm.
3. Thực thi kỹ thuật: Xây dựng hệ thống Auto-Failover với LiteLLM Proxy
Hiện nay, hai công cụ AI Gateway mã nguồn mở và quản trị mạnh mẽ nhất là LiteLLM và Portkey. Chúng cho phép lập trình viên định cấu hình định tuyến (routing) và tự động Failover chỉ bằng một tệp cấu hình YAML đơn giản.
Dưới đây là file cấu hình thực tế giúp bạn chuyển hướng lưu lượng từ Anthropic sang OpenAI và AWS Bedrock khi xảy ra sự cố lỗi mạng (HTTP 429 hoặc HTTP 5xx):
model_list:
- model_name: premium-coder
litellm_params:
model: claude-3-5-sonnet-20241022
api_provider: anthropic
api_key: "os.environ/ANTHROPIC_API_KEY"
rpm: 1000
- model_name: premium-coder
litellm_params:
model: gpt-4o
api_provider: openai
api_key: "os.environ/OPENAI_API_KEY"
rpm: 2000
- model_name: premium-coder
litellm_params:
model: bedrock/us-east-1.anthropic.claude-3-5-sonnet-v2:0
aws_access_key_id: "os.environ/AWS_ACCESS_KEY_ID"
aws_secret_access_key: "os.environ/AWS_SECRET_ACCESS_KEY"
aws_region_name: "us-east-1"
router_settings:
routing_strategy: failure-rate-based-routing
allowed_fails: 3
cooldown_time: 300
failover_on_status_codes: [429, 500, 502, 503]
Triển khai Code Client (Python):
Khi sử dụng LiteLLM Gateway, ứng dụng client của bạn sẽ giao tiếp thông qua một endpoint duy nhất chuẩn hóa theo định dạng OpenAI SDK. Nếu sự cố API Anthropic xảy ra, Gateway sẽ tự động định tuyến ngầm mà code ứng dụng không hề phải thay đổi logic handle error phức tạp:
import openai
# Kết nối trực tiếp đến LiteLLM Gateway
client = openai.OpenAI(
api_key="anything",
base_url="http://localhost:4000"
)
try:
response = client.chat.completions.create(
model="premium-coder",
messages=[{"role": "user", "content": "Viết script Python tối ưu hóa thuật toán Dijkstra."}],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="")
except Exception as e:
print(f"\n[Fatal Error] Toàn bộ hệ thống Multi-LLM bị sập: {str(e)}")
4. 3 Chiến thuật Failover nâng cao dành cho Tech Lead
Để vận hành hệ thống AI quy mô lớn ổn định tuyệt đối, việc đổi model khi gặp lỗi là chưa đủ. Các Solution Architect cần áp dụng 3 triết lý thiết kế sau:
- Cơ chế Exponential Backoff có nhiễu (Jitter): Khi nhận mã lỗi HTTP 429 (Rate Limited), việc lập tức thử lại (retry) sẽ tạo ra hiệu ứng nghẽn cổ chai (thundering herd problem), khiến server của nhà cung cấp càng bị quá tải. Chúng ta cần thiết lập thời gian chờ tăng dần theo cấp số nhân kèm theo hệ số nhiễu ngẫu nhiên (Jitter) để phân rã các yêu cầu thử lại.
- Ngắt mạch chủ động (Circuit Breaker): Nếu mô hình chính liên tục trả về lỗi 5xx trong 3 lần liên tiếp, hệ thống cần tự động kích hoạt trạng thái "mở mạch" (Open State), chuyển hướng toàn bộ lưu lượng sang mô hình dự phòng ngay lập tức trong vòng 5 đến 10 phút mà không cần gửi yêu cầu thử thách đến mô hình chính nữa để tiết kiệm tài nguyên và giảm thiểu độ trễ (latency).
- Suy giảm tính năng mượt mà (Graceful Degradation): Thay vì sử dụng các mô hình thương mại đắt đỏ khác để dự phòng, các tác vụ phân tích đơn giản nên có phương án fallback xuống các mô hình nhỏ siêu rẻ (như GPT-4o-mini hoặc Llama 3 8B) để duy trì hoạt động cốt lõi của sản phẩm mà không làm tăng vọt chi phí vận hành.

5. Tự chủ công nghệ bằng Local / Open-Source LLMs: Hàng phòng ngự cuối cùng
Sự can thiệp sâu sắc của chính phủ vào tầng phân phối API đã dập tắt hoàn toàn ảo tưởng về một hệ thống AI phụ thuộc hoàn toàn vào bên thứ ba. Để bảo vệ dữ liệu doanh nghiệp và đảm bảo tính tự chủ tuyệt đối, việc xây dựng và tự host các mô hình mã nguồn mở (Open-Source LLMs) trên hạ tầng riêng (On-premise hoặc Private Cloud) đang trở thành xu hướng bắt buộc.
Sử dụng các công cụ tối ưu hóa hiệu năng inference (suy luận) như vLLM hay Ollama kết hợp với các mô hình hàng đầu hiện nay như Llama 3 (Meta) hay Mistral (Pháp) cho phép bạn xây dựng một cụm máy chủ AI nội bộ mạnh mẽ. Khi cấu hình cụm máy chủ này làm trạm fallback cuối cùng trong AI Gateway của bạn, hệ thống của bạn sẽ được bảo vệ tuyệt đối 100% trước mọi lệnh cấm vận kỹ thuật hay các vụ sập nguồn bất ngờ.
Lời kết
Sự cố API Anthropic vừa qua là một bài học đắt giá, nhưng cũng là một cơ hội lớn để giới công nghệ nhìn nhận lại cách chúng ta thiết kế hệ thống AI. Một ứng dụng bền vững không được phép đặt cược vận mệnh của mình vào bất kỳ một API độc quyền nào. Bằng cách triển khai kiến trúc Multi-LLM, ứng dụng cơ chế Failover thông minh và hướng tới việc tự chủ công nghệ bằng mã nguồn mở, bạn không chỉ giúp doanh nghiệp vượt qua các biến động bất ngờ mà còn nâng tầm tư duy hệ thống lên chuẩn quốc tế.
Hãy bắt tay vào tái cấu trúc hệ thống của bạn ngay hôm nay trước khi sự cố API tiếp theo xảy ra!
Follow HR1Tech, để đón đọc nhiều nội dung bổ ích và hấp dẫn nhé!
HR1Tech - Online Recruitment Platform for the IT Industry
Find jobs and recruitment multi-industry. Discover more at: www.hr1jobs.com